
FLUX.1 Dev
FLUX.1 Dev est un modèle IA texte-vers-image avancé, à poids ouverts et distillé par guidage, développé par Black Forest Labs, offrant une génération d’images d...
3 min de lecture

Modèle d'IA
Stable Diffusion 3.5 Large est le modèle d’IA texte-image le plus avancé de Stability AI, offrant une qualité d’image supérieure, une meilleure fidélité aux prompts et une grande polyvalence à travers un large éventail de styles et de tâches.
Nous regroupons les meilleurs modèles d'IA pour vous aider à générer des images avec des effets et des styles personnalisés.
Stable Diffusion 3.5 Large est le modèle texte-image multimodal phare de Stability AI, sorti en juin 2024. Doté de 8,1 milliards de paramètres et basé sur la nouvelle architecture Multimodal Diffusion Transformer (MMDiT), il offre une fidélité d’image inégalée, une grande diversité de styles et une précision remarquable dans l’interprétation des prompts. SD 3.5 Large établit une nouvelle référence pour les applications créatives et professionnelles, surpassant à la fois les versions précédentes et de nombreux concurrents contemporains dans le domaine de l’IA générative.
| Fonctionnalité | SD 3.0 / 3.5 Medium | SD 3.5 Large |
|---|---|---|
| Paramètres | 2B - 3B | 8,1B |
| Architecture | DiT, variantes U-Net | Multimodal DiT (MMDiT) |
| Fidélité aux prompts | Bonne | Excellente |
| Typographie | Bonne | À la pointe |
| Résolution d’image | Jusqu’à 1024x1024 | Jusqu’à 2048x2048 |
| Polyvalence des styles | Élevée | Très élevée |
| Latence | Faible-Moyenne | Moyenne |
Stable Diffusion 3.5 Large est conçu pour concurrencer directement des modèles comme Midjourney v6 et DALL·E 3. Dans des benchmarks indépendants et des évaluations d’utilisateurs, SD 3.5 Large démontre :
Pour utiliser ce modèle en Python avec la bibliothèque diffusers :
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large",
torch_dtype="float16",
variant="fp16"
)
pipeline.to("cuda")
prompt = "A futuristic cityscape at sunset, ultra high resolution, photorealistic"
result = pipeline(prompt)
result.images[0].save("sd35_large_sample.png")
Remarque : L’accès au modèle sur Hugging Face peut nécessiter l’acceptation de conditions de licence spécifiques.
Stability AI a intégré des filtres de sécurité avancés et des mesures d’évaluation d’intégrité pour minimiser la génération de contenus nuisibles ou inappropriés. Il est recommandé aux utilisateurs de consulter la carte du modèle et de respecter les directives éthiques lors du déploiement de SD 3.5 Large dans des projets publics ou commerciaux.
Pour plus de détails, lisez l’annonce officielle de la sortie ou consultez la page du modèle sur HuggingFace .
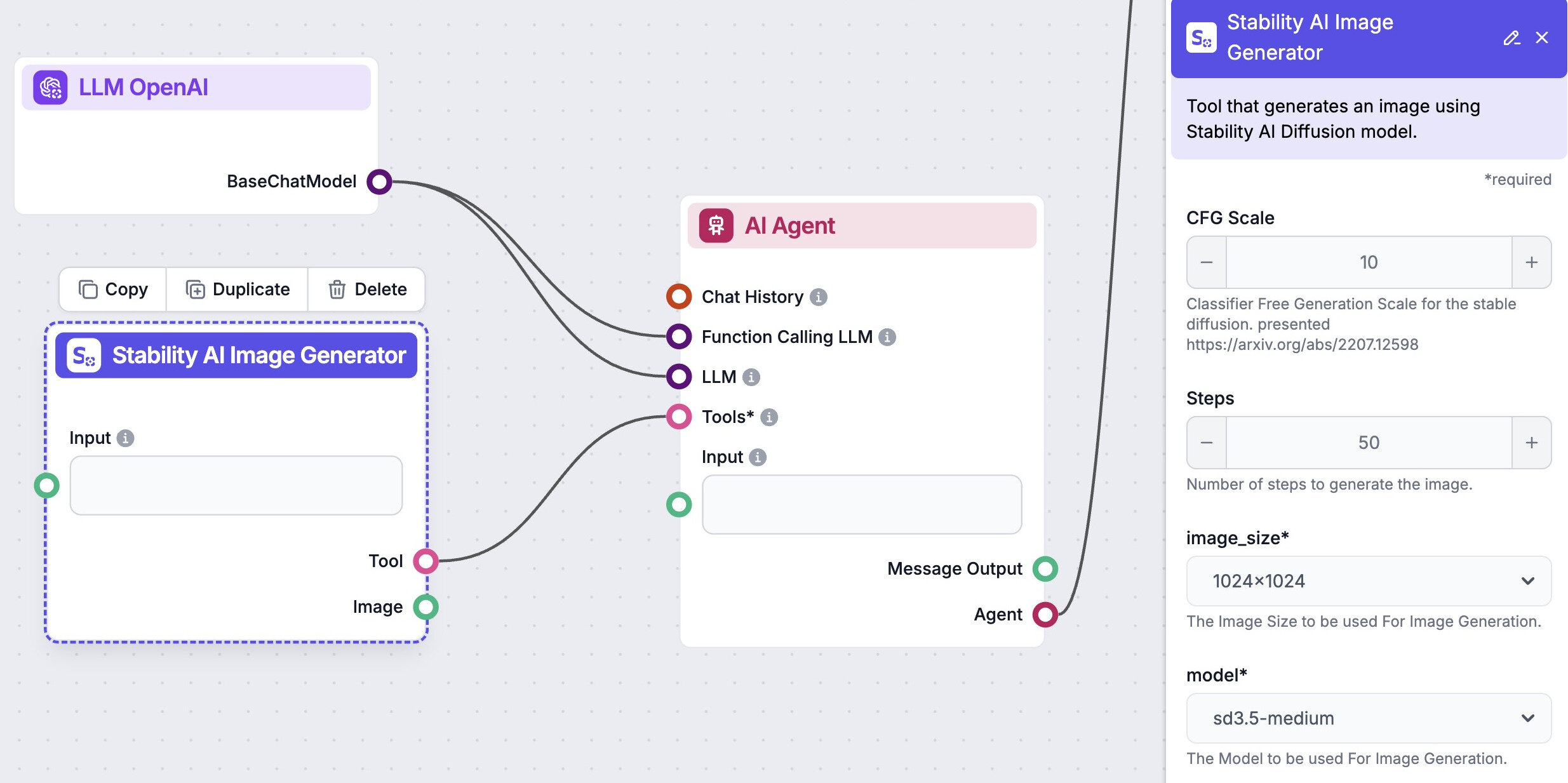
Automatisez votre génération d'images avec les Agents IA
FlowHunt est bien plus qu’une plateforme de génération d’images. Vous pouvez automatiser votre processus de génération d’images avec des Agents IA ou des Équipes dans AI Studio. Créez des visuels impressionnants en quelques secondes, adaptés à vos besoins. Que vous ayez besoin de photos de produits, de visuels marketing ou d’œuvres d’art uniques, notre plateforme vous permet de donner vie à vos idées facilement. AI Studio prend en charge une large gamme de modèles de génération d’images.
Exemples d’utilisation :
Remarque : Toutes les images de cette page ont été générées automatiquement par un agent IA et un flux de travail automatisé.
Laissez-nous vous aider à automatiser vos tâches de marketing. Notre plateforme vous permet de créer des chatbots IA, des agents et des flux de travail personnalisés qui peuvent gérer une large gamme de tâches, du support client à la génération de contenu.
Générez des visuels marketing professionnels en quelques secondes. Notre IA crée des images impressionnantes qui maintiennent la cohérence de votre marque à travers toutes vos campagnes sans services de design coûteux.
Produisez efficacement de grands volumes de contenu personnalisé. Créez des centaines d'images, d'articles de blog et de matériels marketing simultanément avec nos flux de travail d'automatisation IA.
Entraînez des modèles d'IA sur les éléments de votre marque pour créer des visuels uniques et fidèles à votre marque pour n'importe quelle campagne. Maintenez une identité visuelle cohérente sur tous les canaux marketing avec la technologie d'entraînement de personnages.
Explorez d'autres modèles d'IA que vous pouvez utiliser pour générer des images sur notre plateforme
FLUX.1 Dev est un modèle IA texte-vers-image avancé, à poids ouverts et distillé par guidage, développé par Black Forest Labs, offrant une génération d’images d...

FLUX.1 Schnell est un modèle d’IA texte-vers-image ultrarapide et de pointe, développé par Black Forest Labs, pour une génération d’images rapide et de haute qu...

Ideogram V3 Équilibré est un modèle d'IA avancé pour la génération d’images à partir de texte, optimisé pour offrir un équilibre remarquable entre rapidité, qua...

Ideogram V3 Turbo est un modèle IA de conversion texte-image de pointe, excellent en photoréalisme, design créatif et rendu avancé de texte, avec des fonctionna...

Qualité Ideogram V3 est un modèle d'IA texte-vers-image de premier plan qui offre un réalisme époustouflant, des designs créatifs et des styles cohérents, établ...

Ideogram V2 est un modèle d'IA texte-vers-image avancé offrant un réalisme de pointe, des capacités de design graphique et un rendu de texte inégalé. Il propose...
Ideogram V2 Turbo est un modèle d'IA de pointe conçu pour une génération texte-vers-image rapide et de haute qualité, excellant dans la compréhension des prompt...
Ideogram V2A est un modèle d'IA texte-vers-image avancé et efficace, offrant une génération plus rapide et économique avec des options polyvalentes de styles et...
Ideogram V2A Turbo est un modèle d’IA texte-vers-image avancé axé sur une génération d’images ultra-rapide, une qualité de sortie élevée et des capacités robust...

Imagen 3 est le modèle d’IA de génération d’images à partir de texte le plus avancé de Google, offrant une génération d’images photoréalistes, très détaillées e...
Stable Diffusion 3.5 Large Turbo est un modèle d'IA de pointe pour la génération d'images à partir de texte, conçu pour une synthèse d'images ultra-rapide et de...
Stable Diffusion 3.5 Medium est un puissant modèle d'IA conçu pour générer des images de haute qualité avec un style unique.