
FLUX.1 Dev
FLUX.1 Dev is an advanced open-weight, guidance-distilled text-to-image AI model by Black Forest Labs, delivering high-quality image generation for non-commerci...
3 min read

AI Model
Stable Diffusion 3.5 Large is the most advanced text-to-image AI model from Stability AI, offering superior image quality, prompt adherence, and versatility across a wide range of styles and tasks.
We aggregate the best AI models to help you generate images with custom effects and styles.
Stable Diffusion 3.5 Large is the flagship multimodal text-to-image model from Stability AI, released in June 2024. Featuring a massive 8.1 billion parameters and built on the novel Multimodal Diffusion Transformer (MMDiT) architecture, it delivers unmatched image fidelity, style diversity, and prompt accuracy. SD 3.5 Large sets a new benchmark for creative and professional applications, outperforming both previous versions and many contemporary competitors in the generative AI space.
| Feature | SD 3.0 / 3.5 Medium | SD 3.5 Large |
|---|---|---|
| Parameters | 2B - 3B | 8.1B |
| Architecture | DiT, U-Net variants | Multimodal DiT (MMDiT) |
| Prompt Adherence | Good | Excellent |
| Typography | Good | State-of-the-Art |
| Image Resolution | Up to 1024x1024 | Up to 2048x2048 |
| Style Versatility | High | Very High |
| Latency | Low-Medium | Medium |
Stable Diffusion 3.5 Large is designed to compete directly with models like Midjourney v6 and DALL·E 3. In independent benchmarks and user evaluations, SD 3.5 Large demonstrates:
To use this model in Python with the diffusers library:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large",
torch_dtype="float16",
variant="fp16"
)
pipeline.to("cuda")
prompt = "A futuristic cityscape at sunset, ultra high resolution, photorealistic"
result = pipeline(prompt)
result.images[0].save("sd35_large_sample.png")
Note: Access to the model on Hugging Face may require agreeing to specific license terms.
Stability AI has integrated advanced safety filters and integrity evaluation measures to minimize the generation of harmful or inappropriate content. Users are encouraged to review the model card and adhere to ethical guidelines when deploying SD 3.5 Large for public or commercial projects.
For more details, read the official release announcement or visit the HuggingFace model page .
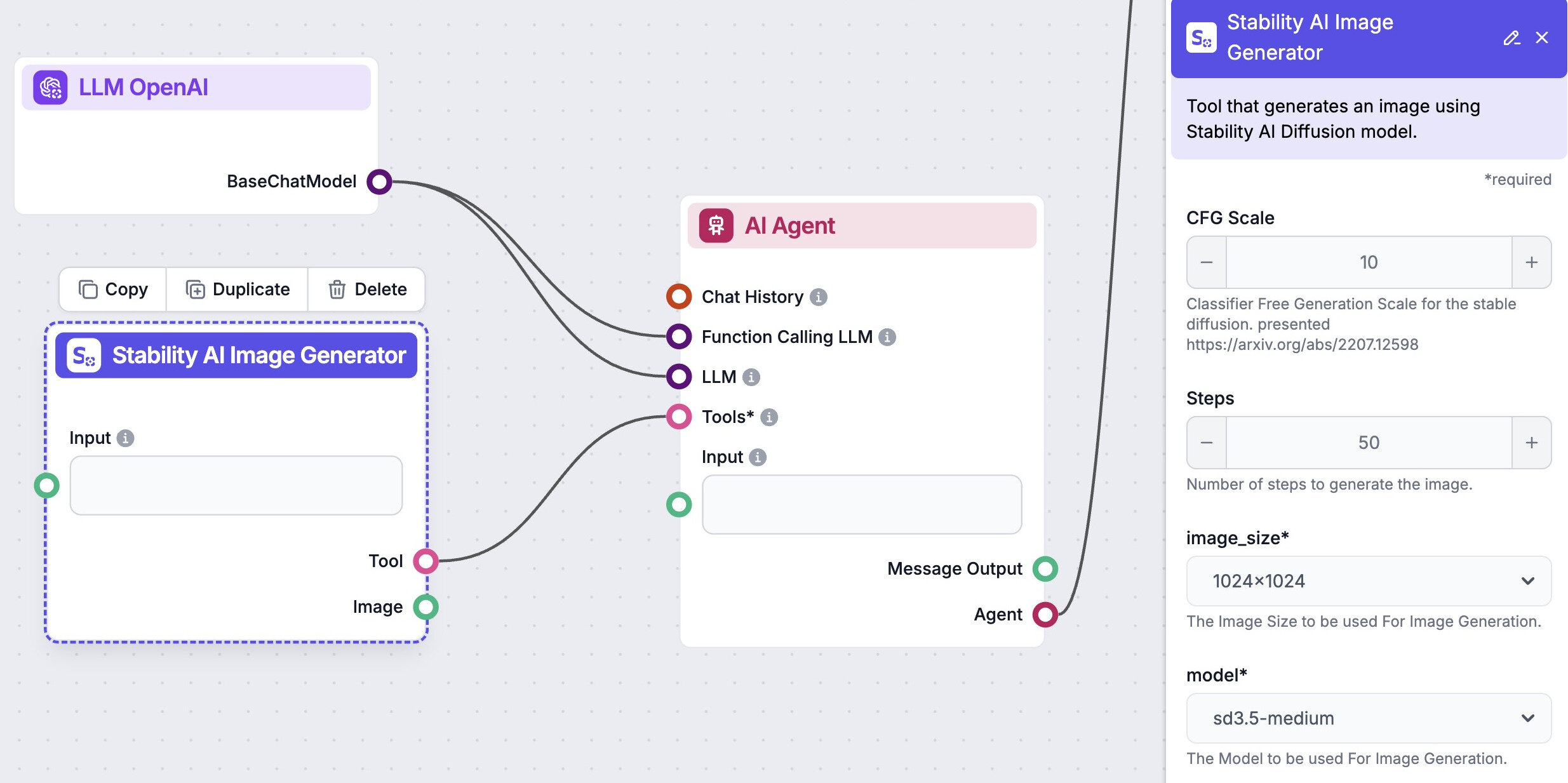
Automate your image generation with AI Agents
Let us help you automate your marketing tasks. Our platform allows you to create custom AI chatbots, agents, and workflows that can handle a wide range of tasks, from customer support to content generation.
Generate professional marketing visuals in seconds. Our AI creates stunning images that maintain brand consistency across all your campaigns without expensive design services.
Produce large volumes of customized content efficiently. Create hundreds of images, blog posts, and marketing materials simultaneously with our AI automation workflows.
Train AI models on your brand assets to create unique, on-brand visuals for any campaign. Maintain consistent visual identity across all marketing channels with character training technology.
Explore other AI models you can use to generate images in our platform
FLUX.1 Dev is an advanced open-weight, guidance-distilled text-to-image AI model by Black Forest Labs, delivering high-quality image generation for non-commerci...

FLUX.1 Schnell is a state-of-the-art, ultra-fast, step-distilled text-to-image AI model developed by Black Forest Labs for rapid, high-quality image generation ...

Ideogram V3 Balanced is an advanced AI model for text-to-image generation, optimized to provide a strong balance between speed, quality, and cost for creative a...

Ideogram V3 Quality is a top-tier text-to-image AI model that delivers stunning realism, creative designs, and consistent styles, setting a new standard in gene...

Ideogram V3 Turbo is a state-of-the-art AI text-to-image model, excelling in photorealism, creative design, and advanced text rendering, with features for consi...

Ideogram V2 is an advanced text-to-image AI model delivering industry-leading realism, graphic design, and text rendering capabilities. It offers enhanced style...
Ideogram V2 Turbo is a cutting-edge AI model designed for rapid, high-quality text-to-image generation, excelling in prompt comprehension, inpainting, and text ...
Ideogram V2A is an advanced, efficient text-to-image AI model delivering faster, cost-effective generation with versatile style and aspect ratio options.
Ideogram V2A Turbo is an advanced AI text-to-image model focused on lightning-fast image generation, high-quality output, and robust inpainting and text renderi...

Imagen 3 is Google's most advanced text-to-image AI model, offering photorealistic, highly detailed, and versatile image generation. It delivers significant imp...
Stable Diffusion 3.5 Large Turbo is a cutting-edge AI model for text-to-image generation, designed for ultra-fast, high-fidelity image synthesis using Multimoda...
Stable Diffusion 3.5 Medium is a powerful AI model designed for generating high-quality images with a unique style.