
FLUX.1 Dev
FLUX.1 Dev är en avancerad öppen AI-modell för text-till-bild från Black Forest Labs, som levererar bildgenerering av hög kvalitet för icke-kommersiella tillämp...
3 min read

AI-modell
Stable Diffusion 3.5 Large är den mest avancerade text-till-bild AI-modellen från Stability AI och erbjuder överlägsen bildkvalitet, följsamhet mot promptar och mångsidighet över ett brett spektrum av stilar och uppgifter.
Vi samlar de bästa AI-modellerna för att hjälpa dig generera bilder med anpassade effekter och stilar.
Stable Diffusion 3.5 Large är Stability AI:s flaggskepp inom multimodala text-till-bild-modeller, lanserad i juni 2024. Med hela 8,1 miljarder parametrar och byggd på den nya Multimodal Diffusion Transformer (MMDiT)-arkitekturen levererar den oöverträffad bildtrohet, stilmångfald och precision i prompttolkning. SD 3.5 Large sätter en ny standard för kreativa och professionella tillämpningar och överträffar både tidigare versioner och många samtida konkurrenter inom generativ AI.
| Funktion | SD 3.0 / 3.5 Medium | SD 3.5 Large |
|---|---|---|
| Parametrar | 2M - 3M | 8,1M |
| Arkitektur | DiT, U-Net-varianter | Multimodal DiT (MMDiT) |
| Promptföljsamhet | Bra | Utmärkt |
| Typografi | Bra | Ledande i branschen |
| Bildupplösning | Upp till 1024x1024 | Upp till 2048x2048 |
| Stilflexibilitet | Hög | Mycket hög |
| Latens | Låg-Medel | Medel |
Stable Diffusion 3.5 Large är utformad för att direkt konkurrera med modeller som Midjourney v6 och DALL·E 3. I oberoende tester och användarutvärderingar visar SD 3.5 Large:
För att använda denna modell i Python med biblioteket diffusers:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large",
torch_dtype="float16",
variant="fp16"
)
pipeline.to("cuda")
prompt = "A futuristic cityscape at sunset, ultra high resolution, photorealistic"
result = pipeline(prompt)
result.images[0].save("sd35_large_sample.png")
Observera: Tillgång till modellen på Hugging Face kan kräva att du godkänner specifika licensvillkor.
Stability AI har integrerat avancerade säkerhetsfilter och integritetsbedömningar för att minimera generering av skadligt eller olämpligt innehåll. Användare uppmanas att läsa modellkortet och följa etiska riktlinjer vid användning av SD 3.5 Large för publika eller kommersiella projekt.
För mer information, läs det officiella lanseringsmeddelandet eller besök HuggingFace-modelsidan .
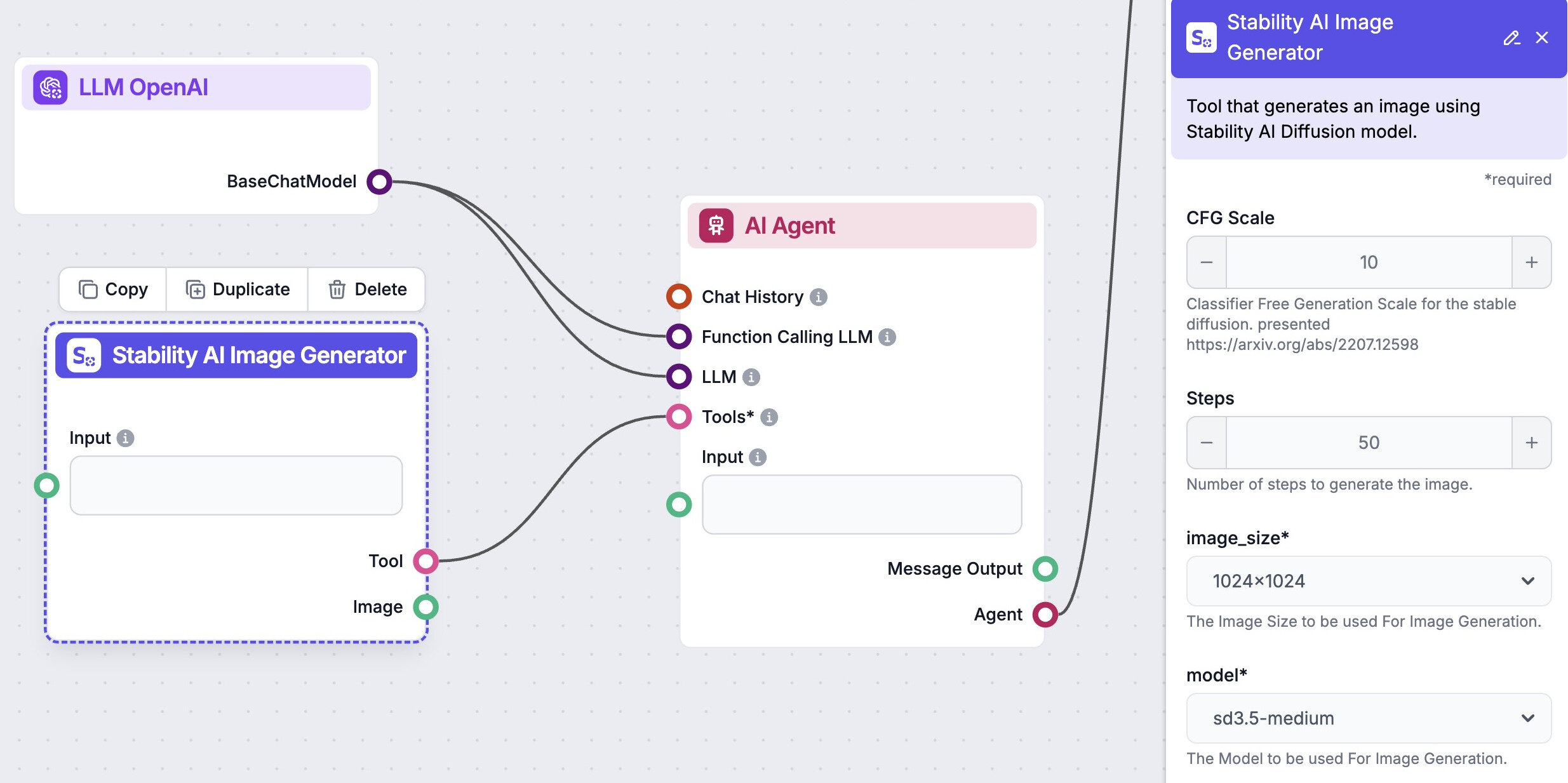
Automatisera din bildgenerering med AI-agenter
Låt oss hjälpa dig att automatisera dina marknadsföringsuppgifter. Vår plattform låter dig skapa anpassade AI-chatbots, agenter och arbetsflöden som kan hantera ett brett spektrum av uppgifter, från kundstöd till innehållsskapande.
Generera professionellt marknadsföringsmaterial på sekunder. Vår AI skapar fantastiska bilder som behåller varumärkeskonsistens i alla dina kampanjer utan dyra designtjänster.
Producera stora volymer av anpassat innehåll effektivt. Skapa hundratals bilder, blogginlägg och marknadsföringsmaterial samtidigt med våra AI-automatiseringsarbetsflöden.
Träna AI-modeller på dina varumärkestillgångar för att skapa unika visuella element som följer ditt varumärke för alla kampanjer. Bibehåll en konsekvent visuell identitet i alla marknadsföringskanaler med karaktärsträningsteknologi.
Utforska andra AI-modeller du kan använda för att generera bilder i vår plattform
FLUX.1 Dev är en avancerad öppen AI-modell för text-till-bild från Black Forest Labs, som levererar bildgenerering av hög kvalitet för icke-kommersiella tillämp...

FLUX.1 Schnell är en toppmodern, ultrasnabb, steg-destillerad text-till-bild AI-modell utvecklad av Black Forest Labs för snabb och högkvalitativ bildgenerering...

Ideogram V3 Balanced är en avancerad AI-modell för text-till-bild-generering, optimerad för att erbjuda en stark balans mellan hastighet, kvalitet och kostnad f...

Ideogram V3 Kvalitet är en text-till-bild AI-modell av högsta klass som levererar fantastisk realism, kreativa designer och konsekventa stilar, och sätter en ny...

Ideogram V3 Turbo är en toppmodern AI text-till-bild-modell som utmärker sig inom fotorealism, kreativ design och avancerad textrendering, med funktioner för ko...

Ideogram V2 är en avancerad text-till-bild AI-modell som levererar marknadsledande realism, grafisk design och textåtergivningsförmåga. Den erbjuder förbättrad ...
Ideogram V2 Turbo är en banbrytande AI-modell utformad för snabb, högkvalitativ text-till-bild-generering, med utmärkt förmåga till promptförståelse, inpainting...
Ideogram V2A är en avancerad och effektiv text-till-bild AI-modell som erbjuder snabbare, kostnadseffektiv generering med mångsidiga stil- och bildförhållandeal...
Ideogram V2A Turbo är en avancerad AI-modell för text-till-bild som fokuserar på blixtsnabb bildgenerering, högkvalitativ output och robusta förmågor för inpain...

Imagen 3 är Googles mest avancerade AI-modell för text-till-bild, som erbjuder fotorealistisk, mycket detaljerad och mångsidig bildgenerering. Den levererar bet...
Stable Diffusion 3.5 Large Turbo är en toppmodern AI-modell för text-till-bild-generering, utformad för ultrasnabb och högupplöst bildsyntes med Multimodal Diff...
Stable Diffusion 3.5 Medium är en kraftfull AI-modell utvecklad för att generera högkvalitativa bilder med en unik stil.