
FLUX.1 Dev
FLUX.1 Dev 是 Black Forest Labs 推出的先进开源权重、引导蒸馏文本生成图像 AI 模型,为非商业应用提供高质量图像生成能力。
1 分钟阅读

人工智能模型
Stable Diffusion 3.5 Large 是 Stability AI 推出的最先进文本生成图像 AI 模型,具备卓越的图像质量、指令遵循性以及在多种风格和任务中的多样化表现。
Stable Diffusion 3.5 Large 是 Stability AI 于 2024 年 6 月发布的旗舰级多模态文本生成图像模型。该模型拥有高达 81 亿参数,基于全新的多模态扩散变换器(MMDiT)架构,能够实现无与伦比的图像逼真度、风格多样性和指令精准度。SD 3.5 Large 为创意和专业应用树立了新标杆,在生成式 AI 领域超越了以往版本和当下许多竞品。
| 功能 | SD 3.0 / 3.5 Medium | SD 3.5 Large |
|---|---|---|
| 参数量 | 20 亿 - 30 亿 | 81 亿 |
| 架构 | DiT, U-Net 变体 | 多模态 DiT (MMDiT) |
| 指令遵循性 | 良好 | 卓越 |
| 排版能力 | 良好 | 行业领先 |
| 图像分辨率 | 最高 1024x1024 | 最高 2048x2048 |
| 风格多样性 | 高 | 非常高 |
| 生成延迟 | 低-中 | 中等 |
Stable Diffusion 3.5 Large 旨在直接对标如 Midjourney v6 和 DALL·E 3 等模型。在独立基准测试和用户评测中,SD 3.5 Large 展现出:
要在 Python 中通过 diffusers 库使用该模型:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large",
torch_dtype="float16",
variant="fp16"
)
pipeline.to("cuda")
prompt = "A futuristic cityscape at sunset, ultra high resolution, photorealistic"
result = pipeline(prompt)
result.images[0].save("sd35_large_sample.png")
注意: 在 Hugging Face 上访问该模型可能需要同意特定许可条款。
Stability AI 集成了先进的安全过滤和合规性评估措施,以最大限度减少有害或不当内容的生成。建议用户查阅 模型卡 ,并在将 SD 3.5 Large 应用于公共或商业项目时遵循伦理规范。
如需了解更多详情,请参阅 官方发布公告 或访问 HuggingFace 模型页面 。
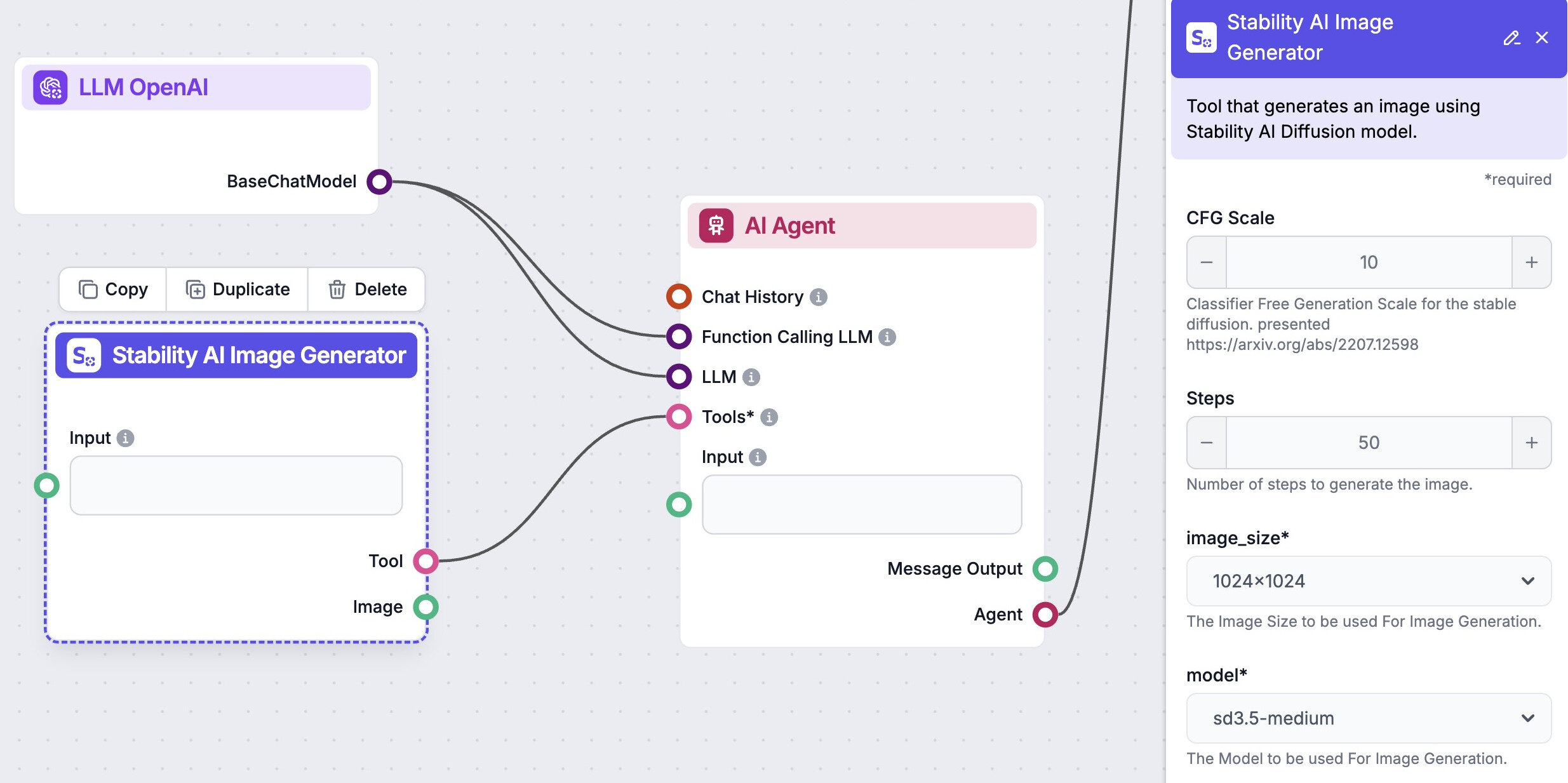
使用人工智能代理自动化您的图像生成
探索您可以在我们平台上使用的其他人工智能模型来生成图像
FLUX.1 Dev 是 Black Forest Labs 推出的先进开源权重、引导蒸馏文本生成图像 AI 模型,为非商业应用提供高质量图像生成能力。

FLUX.1 Schnell 是由 Black Forest Labs 开发的一款最先进、超高速、采用 120 亿参数矫正流变换器架构的分步蒸馏文本生成图像 AI 模型,可实现快速、高质量图像生成。...

Ideogram V3 Turbo 是一款最先进的 AI 文生图模型,在照片级真实感、创意设计和高级文本渲染方面表现卓越,具备一致的风格控制和专业级图像合成功能。...

Ideogram V3 高质量版是一款顶级的文生图 AI 模型,能够呈现惊人的真实感、创意设计和一致的风格,为生成式媒体树立了新的标杆。...

Ideogram V3 平衡版是一款先进的文本生成图像 AI 模型,专为在创意与专业应用中实现速度、质量与成本的最佳平衡而优化。

Ideogram V2 是一款先进的文本生成图像 AI 模型,具备业界领先的真实感、图形设计和文本渲染能力。它提供了增强的风格控制、色彩调色板指定,以及一流的文本与图像对齐效果。...
Ideogram V2 Turbo 是一款前沿的 AI 模型,专为高速、高质量的文生图生成而设计,在理解提示词、图像局部修复和图像中文字渲染方面表现卓越。...
Ideogram V2A 是一款先进高效的文本生成图像 AI 模型,能够更快、更经济地生成图片,并支持多样化的风格和长宽比选择。
Ideogram V2A Turbo 是一款先进的 AI 文生图模型,专注于超快的图像生成、高质量输出,以及强大的局部修复和文本渲染能力。...

Imagen 3 是谷歌最先进的文本生成图片 AI 模型,能够生成高度逼真、细节丰富且多样化的图像。与之前的模型相比,它在图像质量、提示理解和伪影减少方面有了显著提升。...
Stable Diffusion 3.5 Large Turbo 是一款用于文本到图像生成的尖端 AI 模型,采用多模态扩散变换器(MMDiT)架构和对抗扩散蒸馏(ADD),能够实现超快且高保真的图像合成。...
Stable Diffusion 3.5 Medium 是一款强大的 AI 模型,专为生成具有独特风格的高质量图像而设计。