


















































FLUX.1 Dev
FLUX.1 Dev 是 Black Forest Labs 推出的先进开源权重、引导蒸馏文本生成图像 AI 模型,为非商业应用提供高质量图像生成能力。
1 分钟阅读

人工智能模型
Stable Diffusion 3.5 Medium 是一款强大的 AI 模型,专为生成具有独特风格的高质量图像而设计。
使用Stable Diffusion 3.5 Medium生成的人工智能图像
Stable Diffusion 3.5 Medium 由 Stability AI 于 2024 年 10 月发布,是文本到图像生成领域的重要进步,代表了极受欢迎的 Stable Diffusion 系列的最新发展。该模型专为在生成速度、多样性和高图像质量之间实现平衡而设计,适用于广泛的创意和商业应用场景。
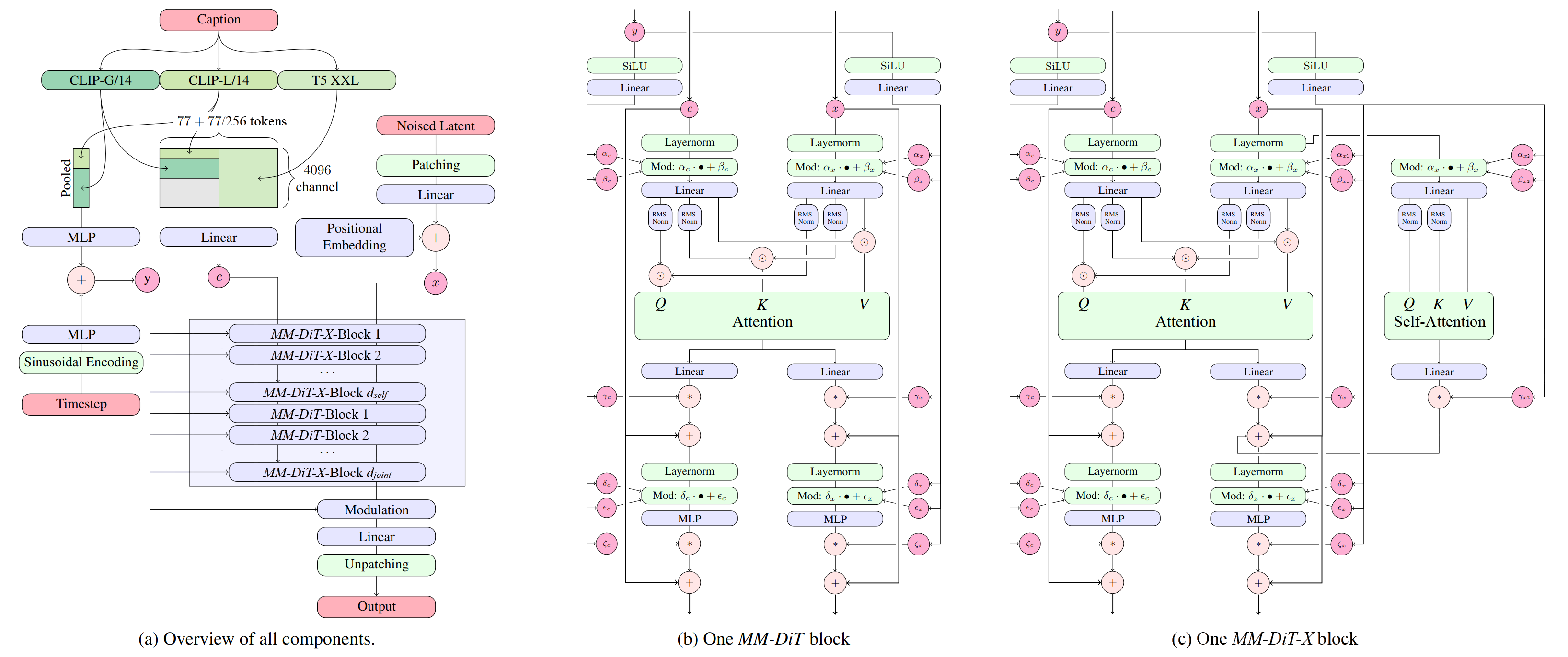
Stable Diffusion 3.5 Medium 的核心是升级版的 MMDiT-X(多模态扩散变换器-X) 架构。该模型拥有约 25 亿参数,在计算效率与表达能力之间取得了理想的平衡。
主要技术改进包括:

| 特性 | SD 3.0 Medium | SD 3.5 Medium | 改进点 |
|---|---|---|---|
| 参数量 | ~12亿 | 25亿 | 更高保真度 |
| 核心架构 | MMDiT | MMDiT-X | 更细致的提示理解 |
| 图像质量 | 良好 | 优秀 | 更清晰、更细腻 |
| 负面提示 | 基础 | 高级 | 输出更可靠 |
| 速度 | 快速 | 快速 | 保持一致 |
3.5 Medium 的优势:
Stable Diffusion 3.5 Medium 在多个核心领域媲美甚至超越了其它开源或闭源的文本到图像模型:
以下是 Stable Diffusion 3.5 Medium 生成的部分图片,展现了其对复杂提示的高准确性和艺术表现力。
Stable Diffusion 3.5 Medium 是一款领先的文本到图像生成 AI 模型,推动了开源生成式 AI 的新高度。通过先进的架构、强大的训练以及社区驱动的发展,树立了图像质量、可控性和效率的新标杆。
如需了解更多详情和示例图片,请访问 官方 Stability AI 发布页 及 Hugging Face 模型卡 。
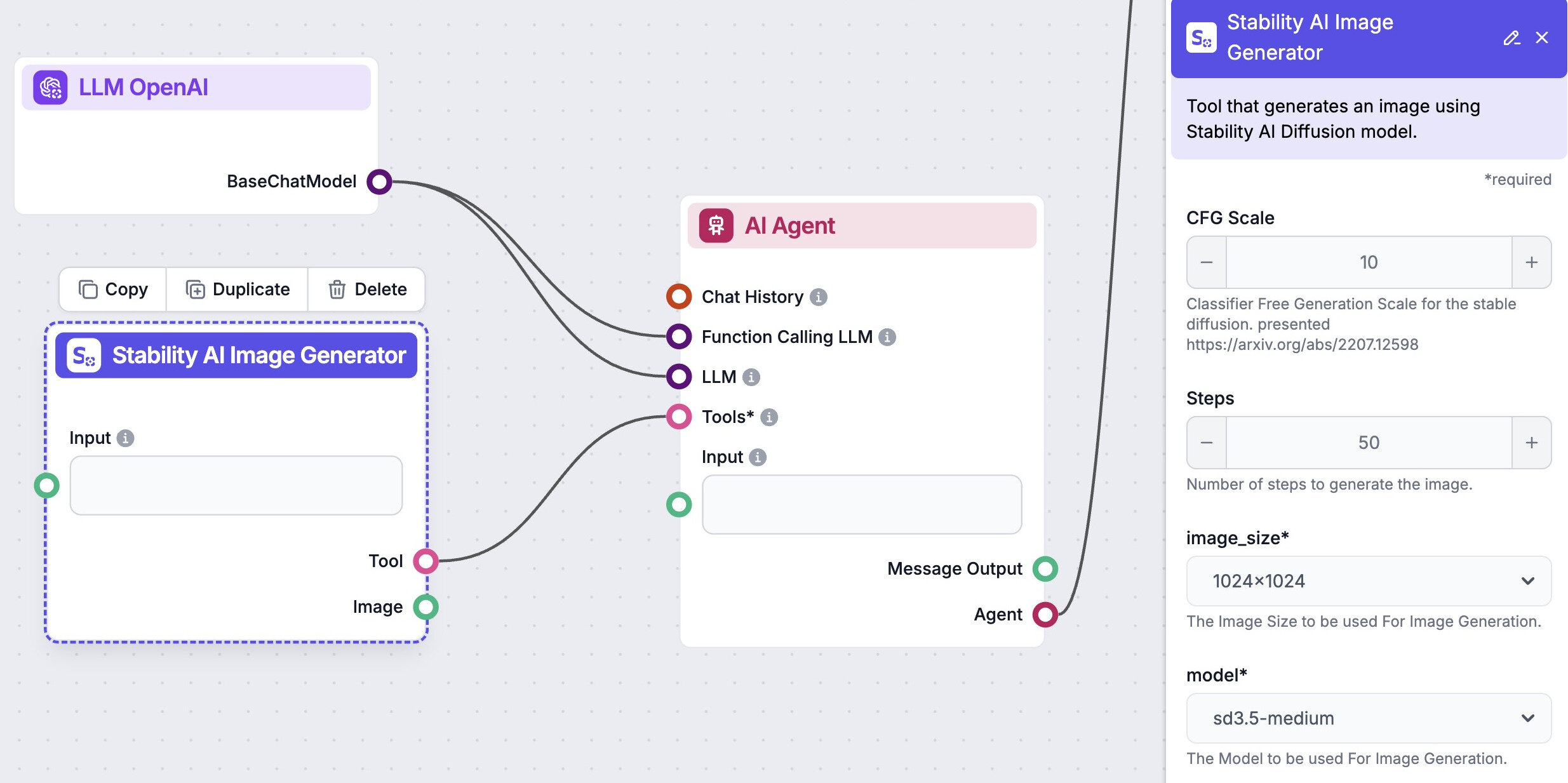
使用人工智能代理自动化您的图像生成
探索您可以在我们平台上使用的其他人工智能模型来生成图像
FLUX.1 Dev 是 Black Forest Labs 推出的先进开源权重、引导蒸馏文本生成图像 AI 模型,为非商业应用提供高质量图像生成能力。

FLUX.1 Schnell 是由 Black Forest Labs 开发的一款最先进、超高速、采用 120 亿参数矫正流变换器架构的分步蒸馏文本生成图像 AI 模型,可实现快速、高质量图像生成。...

Ideogram V3 Turbo 是一款最先进的 AI 文生图模型,在照片级真实感、创意设计和高级文本渲染方面表现卓越,具备一致的风格控制和专业级图像合成功能。...

Ideogram V3 高质量版是一款顶级的文生图 AI 模型,能够呈现惊人的真实感、创意设计和一致的风格,为生成式媒体树立了新的标杆。...

Ideogram V3 平衡版是一款先进的文本生成图像 AI 模型,专为在创意与专业应用中实现速度、质量与成本的最佳平衡而优化。

Ideogram V2 是一款先进的文本生成图像 AI 模型,具备业界领先的真实感、图形设计和文本渲染能力。它提供了增强的风格控制、色彩调色板指定,以及一流的文本与图像对齐效果。...
Ideogram V2 Turbo 是一款前沿的 AI 模型,专为高速、高质量的文生图生成而设计,在理解提示词、图像局部修复和图像中文字渲染方面表现卓越。...
Ideogram V2A 是一款先进高效的文本生成图像 AI 模型,能够更快、更经济地生成图片,并支持多样化的风格和长宽比选择。
Ideogram V2A Turbo 是一款先进的 AI 文生图模型,专注于超快的图像生成、高质量输出,以及强大的局部修复和文本渲染能力。...

Imagen 3 是谷歌最先进的文本生成图片 AI 模型,能够生成高度逼真、细节丰富且多样化的图像。与之前的模型相比,它在图像质量、提示理解和伪影减少方面有了显著提升。...
Stable Diffusion 3.5 Large 是 Stability AI 推出的最先进文本生成图像 AI 模型,具备卓越的图像质量、指令遵循性以及在多种风格和任务中的多样化表现。...
Stable Diffusion 3.5 Large Turbo 是一款用于文本到图像生成的尖端 AI 模型,采用多模态扩散变换器(MMDiT)架构和对抗扩散蒸馏(ADD),能够实现超快且高保真的图像合成。...